AIバイアスは、学習データやアルゴリズムに潜む人間の偏見から生じ、医療や採用など多様な分野で不公平な結果を招いています。
総務省・経済産業省による「AI 事業者ガイドライン(第1.01版)」では、AIシステムにおけるバイアスの問題を取り上げ、AIの開発者、提供者、利用者のそれぞれが、AIの公平性を確保するためにバイアスを考慮する責任があることを明記しています。
このコラムでは、AIバイアスの事例と要因、AIの公平性に関する指針やツールについてわかりやすく解説します。
Column / コラム
HOME > コラム > ものづくり > AIバイアスが社会を歪める? AIの公平性を守るための方策とは
ものづくり IoT モビリティ
AIバイアスは、学習データやアルゴリズムに潜む人間の偏見から生じ、医療や採用など多様な分野で不公平な結果を招いています。
総務省・経済産業省による「AI 事業者ガイドライン(第1.01版)」では、AIシステムにおけるバイアスの問題を取り上げ、AIの開発者、提供者、利用者のそれぞれが、AIの公平性を確保するためにバイアスを考慮する責任があることを明記しています。
このコラムでは、AIバイアスの事例と要因、AIの公平性に関する指針やツールについてわかりやすく解説します。
AIの利用が急速に拡大し、使用される場面がますます拡大しています。
研究やビジネス、意思決定などでも使用されることから、AIが人間社会に与える影響は非常に強くなっています。
人生に大きな影響を与えうるAIバイアスの事例をみてみましょう。
たとえば、過去の雇用履歴から応募者のスコアを計算したAI雇用システムで女性が差別された事例があります。*1
Amazonの採用エンジンでは、過去10年間のレジュメが学習に使用されていた影響で、それまで男性の多かったソフトウェア開発や技術のポジションで、女性の評価が自動的に下げられていました。
また、健康リスク予測のアルゴリズムの偏りが原因で、黒人の患者に必要なケアが30%低く見積もられていた事例も発覚しています。
さらに、米国で禁錮刑受刑者の仮釈放の判断材料として再犯率の推定に用いられているCOMPAS再犯予測AIに関する議論もあります。
このAIシステムでは、前科や違反歴のほか、家族や友人の犯罪歴、宗教、年齢、性別、教育、趣味、居住地域など137個の項目をもとにリスクを評価します。*2
それらの項目のなかには「人種」は入っていません。ところが、黒人に不利な評価が行われているという問題提起が契機となり、開発側からの反論やCOMPAS使用自体の違憲性訴訟などさまざまな議論が生じました。
2016年にウィスコンシン州の最高裁判決によって、COMPASの合憲性は肯定されましたが、使用上の制限や注意事項も提示されました。
この事例から、属性を直接使わなくても不公平な問題が生じうることがわかります。
また、公平性の評価指標は正解が決めづらく定義が難しいこと、社会やデータに組み込まれた不公平が存在しうることなども窺えます。
このように、AIの公平性には複雑な要素が絡んでいます。
公平なAIを実現するためには、「望ましくないバイアス」を除去する必要があります。
ただし、このようなバイアスが入り込む要因にはさまざまなものがあり、幅広い対処が求められます。
産業技術総合研究所「機械学習品質マネジメントガイドライン 第四版」(以下、「ガイドライン」)は、以下の3つの観点によって整理・説明しています。 *2
1.社会・システム的なバイアス
2.人の思考・認知に起因するバイアス
3.統計的・技術的なバイアス
それぞれ順番にみていきましょう。
私たちの実生活やシステムには、既に偏りや、歴史的・制度的な偏見がもたらした結果など、さまざまなバイアスが存在しています。
それがAIの訓練用データセット中に、不適切なバイアスとして反映されるおそれがあります。
たとえば採用判断にAIを使う場合、過去の採用プロセスそのものに、気づかない差別性があれば、機械学習が忠実にその傾向を再現してしまいます。
このように、この社会そのものの不公平は、構築プロセスから配慮しなければならない属性などを排除しただけでは、必ずしも公平なシステムができない原因の1つです。
このようなことから、公平性が重要な機械学習利用システムを構築する際には、データそのものの分析だけではなく、社会分析的な視点が必要です。
AIシステムの設計・開発をするのは人間です。したがって、偏った思考・判断が意図せずAIに持ち込まれる可能性があります。
AI品質管理上、重要視されている言葉に「マクナマラの誤謬」というものがあります。これは、定量的な尺度を重視しすぎて物事の大局を見失ってしまうことを指しますが、この言葉は認知バイアスにも当てはまります。
こうしたバイアスは無意識に生じるのが一般的で、そのためコントロールが難しいとされてい
ます。
ただし、典型的な認知バイアスを理解したうえで、異なる属性のステークホルダーを入れたレビューや、定量指標化に先立つ十分な検討などのプロセスを設けることで改善していくことは可能です。
これは、データ収集から機械学習の進め方における、手法的・技術的な問題に起因するバイアスです。
データに関するバイアスには、データを作成する際に偏見や認知バイアスなどによって学習データに偏りが生じる「データバイアス」、予測対象の集団が学習データに含まれていないことで生じる「標本選択バイアス」、少数事例を例外や外れ値として扱うことで生じる「帰納バイアス」があることが指摘されています。*1
ただし、たとえば「シンプソンのパラドックス」など、統計的知識を持つことで対処可能な問題もあります。*2
「シンプソンのパラドックス」とは、2つのデータの属性間になんらかの関連をみつけようとする際に、実はそれらの両方に関与する第3の要因があるのにそれに気づかず学習した場合、現実には存在しない相関関係、あるいは現実とは逆の相関関係を学習してしまう現象を指します。
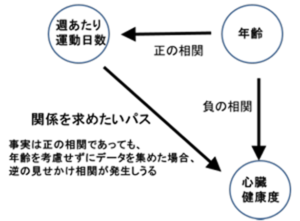
図1 シンプソンのパラドックス
出所)産業技術総合研究所「機械学習品質マネジメントガイドライン 第四版」(2023 年12月12日) p.171
https://www.digiarc.aist.go.jp/publication/aiqm/AIQuality-requirements-rev4.2.0.0113-signed.pdf
たとえば、図1のように「週当たり運動日数」と「心臓健康度」という属性の間にある相関関係を抽出したい場合、実はその裏にその両方に影響を与える「年齢」という第3の要因があります。
しかし、それを考慮せず集めた訓練用データセットで学習した場合、「週当たり運動日数」と「心臓健康度」の本当の関係をみつけることができない可能性があるのです。
こうした統計的知識をもつことによって、統計的・技術的なバイアスは部分的に避けられる可能性もあります。
2024年のUNESCO報告書などでは、特に大規模言語モデル(LLM)はAIバイアスの再生産につながりうることが指摘されています。*1
こうした問題が国際的に広く認知されている現在では、AI品質評価において「公平性」を考慮する動きが加速しています。
内閣府 統合イノベーション戦略推進会議が公表した「人間中心のAI社会原則」では、AIの短所として特にバイアスには注意が必要だと注意喚起しています。*3
AI利用者は、AIの情報リソースとなるデータやアルゴリズムにはバイアスが含まれること、またそれらを望ましくない目的のために利用する者がいることを認識することが重要であるという指摘です。
また、総務省・経済産業省による「AI事業者ガイドライン(第1.01版)」では、AI開発者、AI提供者、AI利用者がぞれぞれ、有害な偏⾒や差別をなくすよう努めるとともに、それでも回避できないバイアスがあることを認識するよう求めています。*4
その上で、それぞれのステークホルダーに対して、以下のような指針を示しています。*5
表1 AI開発者・AI提供者・AI利用者に対する指針

出所)内閣府「AI政策の現状と制度課題」(2024年8月2日)p.8
https://www8.cao.go.jp/cstp/ai/ai_senryaku/11kai/shiryo1.pdf
「ガイドライン」では、公平性要件の分析手法として、比較的容易に相互的な関係を表現できる図表現の1つとして、CBN(Causal Bayesian Networks)を紹介しています。*2
CBN は、属性間の影響をシンプルな依存関係で表現したもので、間接的な影響を含む不公正さが生じるケースをみつけやすくするものです。
下の図2は「大学の合否判定」に関するCBNです。
CBNでは、データ間の因果を矢印で表し、それが「公平」なものか、「不公平」なものか、あるいは、「どちらもあり得る」のかを検討することで、関連性を可視化します。
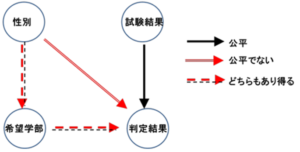
図2 「大学の合否判定」に関するCBN
出所)産業技術総合研究所「機械学習品質マネジメントガイドライン 第四版」(2023 年12月12日) p.170
https://www.digiarc.aist.go.jp/publication/aiqm/AIQuality-requirements-rev4.2.0.0113-signed.pdf
この例では、 「試験結果」から合否判定への影響は「公平」です。
一方で、同一の試験結果に対して、性別によって判定結果が異なりうるのであれば、それは「公平でない」ということになります。
また、「性別」から「希望学部」への関連は、女性が特定の学部を希望しやすいという現実が、女性への暗黙の環境的圧力によるのである場合には、「公平でない」ことになります。
同様に「希望学部」から判定結果への関連も、「女性が希望しがちな学部合否基準点を恣意的に操作する」というケースでは、「公平でない」ことになります。
このように、合否判定に関連するデータ間の関連性を丁寧に分析することで、「性別」-「希望学部」-「判定結果」というパスはその実態やアルゴリズムによって、公平性を損なう要因になることがわかります。
このことは、「性別」という配慮が必要な情報だけを除いて学習させても、「判定結果」の公平性が担保されるとは限らないことを意味します。
大手IT企業も、AIの公平性のためのツールを提供しています。*1
IBM社は、AIバイアス検出・軽減ツールキット「AI Fairness 360(AIF360)」をオープン・ソース・コミュニティーに提供しています。
このツールキットは、ユーザーが機械学習モデルにおけるバイアスを調査、報告、軽減するの
に役立ちます。
また、Google社は、プロダクト公平性テストの手順を学習し、テキスト生成モデルで生成されたデータセットをテストするための「デベロッパーのためのプロダクト公平性テスト」を提供しています。*6
「人間中心のAI社会原則」には、AIにおける公平性および透明性のある意思決定とその結果に対する説明責任が適切に確保される必要があると指摘されています。*3
AIが社会のあらゆる側面に深く浸透する今、この指針のとおり、それぞれのステークホルダーがAIの公平性確保に貢献することが、AIと社会の健全な発展につながるでしょう。