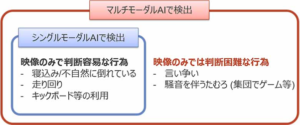
AIはテキスト、音声、画像、センサーから受け取った情報など、多岐にわたるデータを処理の対象にしています。これらの単独のデータの種類を「モーダル」といいます。*1
そして1種類のデータを扱うAIを「シングルモーダルAI」と呼びます。
それに対して「マルチモーダルAI」とは、複数のデータを扱うAIのことです。
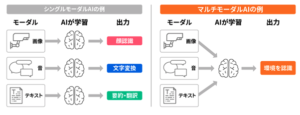
シングルモーダルAIとマルチモーダルAIの違い
(出所:産業技術総合研究所「”マルチモーダルAI”とは?」)
https://www.aist.go.jp/aist_j/magazine/20231129.html
例えば初期のChatGPTの場合は「入力されたテキストデータを分析し、テキストデータで演算結果を出力する」という形で、テキストという1種類のデータのみを処理の対象としていました。
しかしGPT-4では画像とテキストの両方を入力して、2種類のデータを使った演算結果を出力することができるようになっています。
例えば下のようなプロンプトと回答結果です。

GPT-4でのプロンプト入力と解答例
(出所:OpenAI「GPT-4」)
https://openai.com/index/gpt-4-research/
スマホの充電に使えるジョークガジェットの写真を添付した上で「この画像の面白いところは何ですか?写真の順序ごとに説明してください」と質問しています。
皆さんはこの充電ケーブルにはどんなジョークが含まれていると思いますか?
「視覚」を手に入れたGPT-4はこのように回答しています。
3枚の写真からこれがライトニングケーブルだとわかる、とした上でそれぞれの画像について、
1枚目:VGAコネクター(大きい、青い、15ピンの、一般的にモニターに使用されるもの)が充電口に刺さったスマートフォンの画像である
2枚目:VGAコネクターの画像の上に「ライトニングケーブル」アダプターだと書かれた商品の包装である
3枚目:VGAコネクターの先端にライトニングコネクター(iPhoneや他のAoole製品の充電に使用するもの)がついているものの拡大
と説明しています。画像情報をテキスト情報に変換する、という統合ができているのです。
そして、
時代遅れの大きなVGAコネクターが小さくて近代的なスマートフォンの充電口に刺しているというユーモアを示している
という結論を出しています。
また、Googleは「Googleレンズ」アプリをリリースしています。
画像とテキストの両方を入力して検索ができる機能を持っています。例えば自宅にある観葉植物の手入れの方法を知りたいけれど植物の名前がわからない。そんなときに、植物の画像と「手入れ 方法」などといったテキストデータを両方入力して情報を検索できるというものです。